Social XR applications usually require advanced
tracking equipment to control one’s own avatar. We explore if AI-based
co-speech gesture generation techniques can be employed
to compensate for the lack of tracking hardware that many
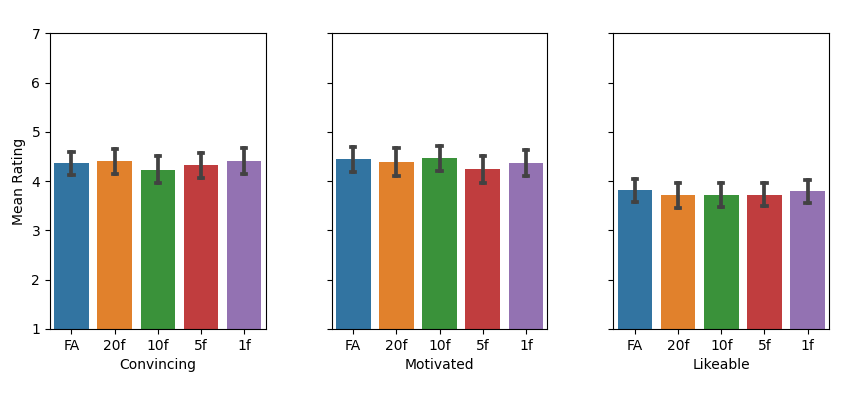
users face. One main challenge is to achieve convincing behavior
quality without introducing too much latency. Previous work
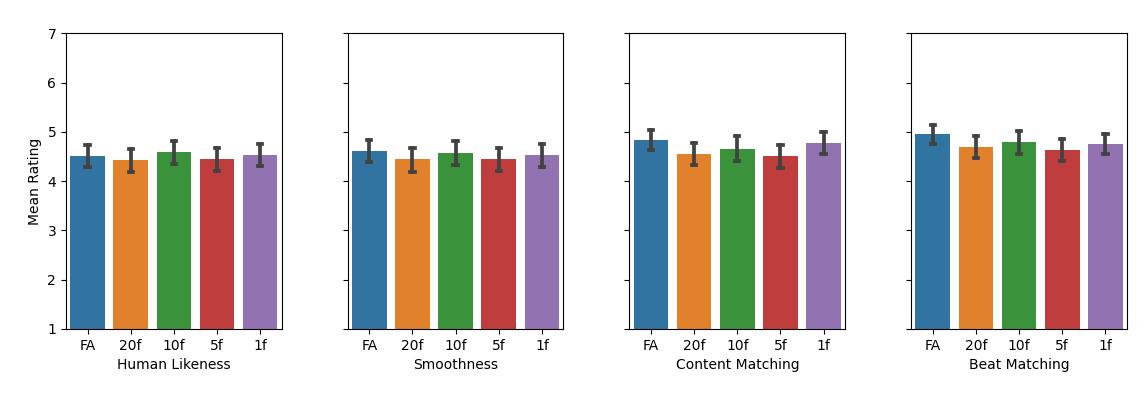
has shown that both depend – in opposite ways – on the
length of the audio chunk the gestures are generated from,
and that gesture quality of existing models declines with lower
chunk sizes while still not reaching sufficiently low latency to
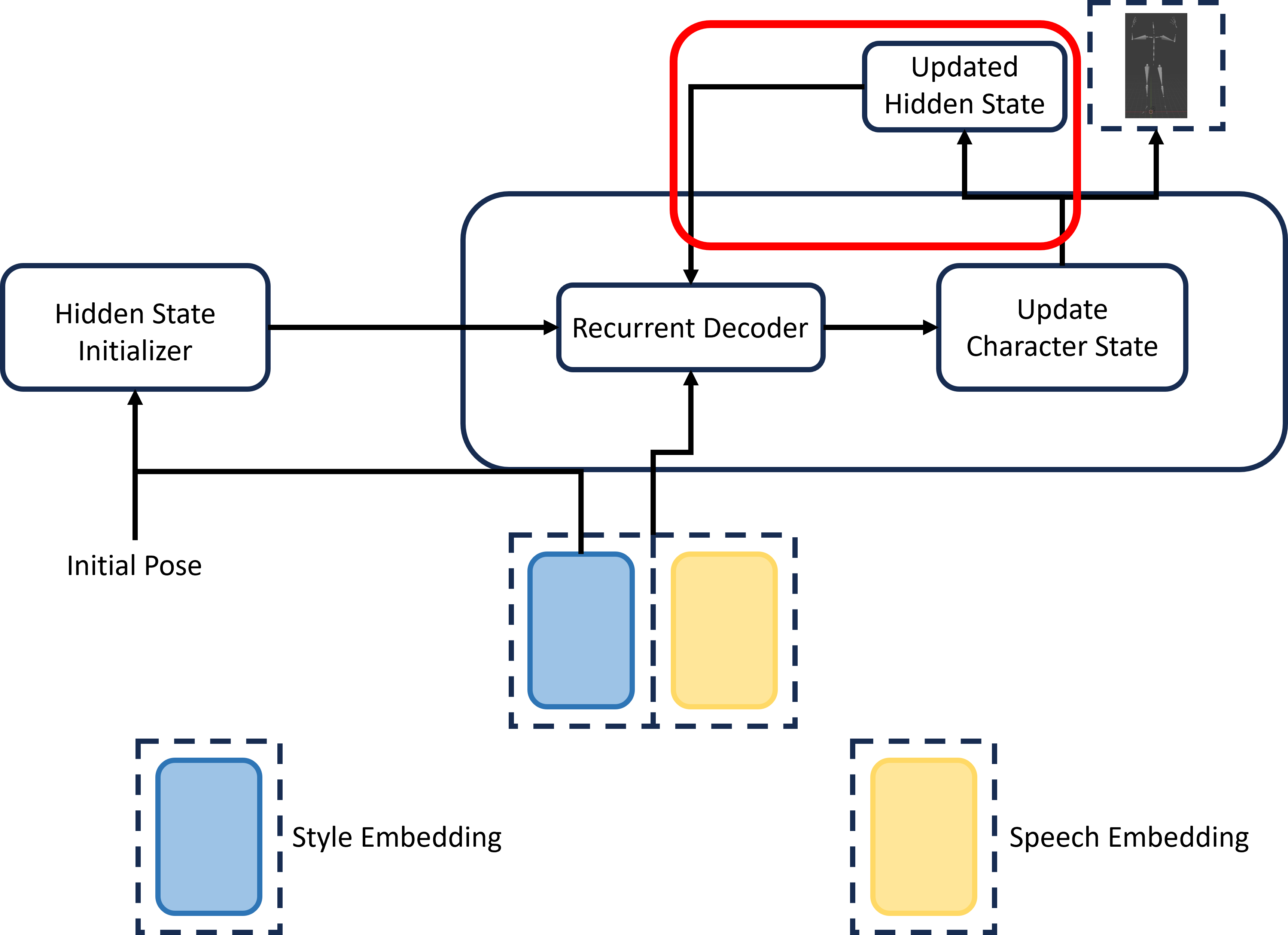
enable fluent interaction. In this paper we present an approach
that is able to generate continuous gesture trajectories frame
by frame, minimizing latency and yielding delays well below
buffer sizes of voice communication systems or video calls.
System Overview
Model Architecture
Video Examples
Chunk Sizes
Ground Truth
Full Audio
0.5s/30f (previous system)
20 frames
10 frames
1 frame
Results
Bibtex
@inproceedings{kromekopp2024rtgest,
title={Minimal Latency Speech-Driven Gesture Generation for Continuous Interaction in Social XR},
author={Krome, Niklas and Kopp, Stefan},
booktitle={Proceedings of the IEEE International Conference on Artificial Intelligence & extended and Virtual Reality},
year={2024}
}